Activité 2 : Le navigateur Web et les échanges entre client et serveur
Interface et utilisation raisonnée d'un navigateur⚓︎

Le Web désigne un ensemble de données reliées entre elles par des liens hypertexte et accessibles sur Internet, formant ainsi une gigantesque « toile d'araignée » mondiale. La première étape, lorsque l'on souhaite accéder à un site Web, est d'entrer l'adresse dans la barre d'adresse d'un navigateur. Cette adresse est appelée URL (Uniform Resource Locator) :
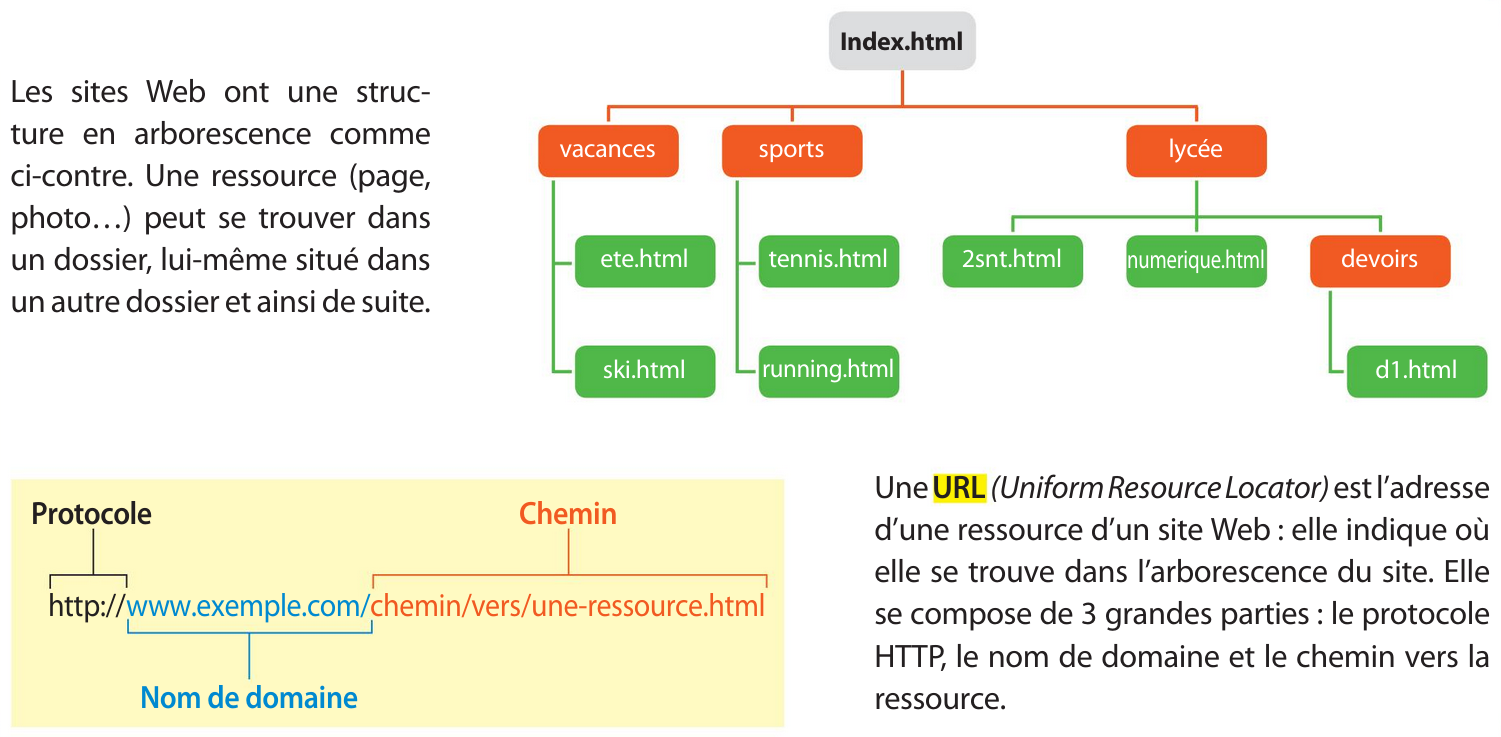
Pour accéder à un site web depuis le navigateur, il faut saisir son adresse dans la barre d'adresse. Cette adresse est appelée URL (Uniform Resource Locator) :
- Le protocole HTTP (HyperText Transfer Protocol) permet de transférer des données sur le Web, c'est lui qui fixe les règles de communication. Il est suivi de deux points et de deux barres obliques (//).
- Le nom de domaine (ou adresse IP) est l'adresse du site qui héberge le site Web. Il se décompose en deux parties : le nom de domaine et l'extension (ex. : .fr, .com, .org, .net...).
- Le chemin d'accès est l'adresse du fichier ou du dossier sur le site. Il est précédé d'une barre oblique (/).
Une variante du protocole HTTP est le protocole HTTPS. Vous trouverez plus d'informations sur cette variante ici : https://developer.mozilla.org/fr/docs/Glossary/HTTPS ; et là : https://fr.wikipedia.org/wiki/Hypertext_Transfer_Protocol_Secure.
Répondre aux questions sur la fiche de travail⚓︎
En vous appuyant sur les documents précédents, répondre aux questions suivantes sur votre fiche de travail et compléter les encadrés « À connaître » 1 et 2.
Question 2
Ouvrir le navigateur Web de votre choix (Google Chrome, Mozilla Firefox, Safari...). Identifier sont les principaux composant de son interface parmi la liste suivante :
- Contenu de la page consultée ;
- Barre d'URL ;
- Boutons de navigation ;
- Paramètres ;
- Onglets ;
- Barre de favoris ;
- Barre de recherche.
En saisissant l'adresse (URL) suivante dans la barre d'adresse du navigateur, vous pourrez accéder à la version en ligne de la fiche de travail du chapitre. On peut décomposer cette adresse en 3 parties :

Question 3
À partir de l'URL précédent, identifier les trois parties le composant et leur attribuer en justifiant les termes "Chemin", "Nom de domaine" et "Protocole".
Question 4
Que signifie HTTP ? Quelle est la différence entre HTTP et HTTPS ?
Question 5
Quels sont les risques liés à l'utilisation du protocole HTTP plutôt que HTTPS ?
Étude de la communication entre le client (navigateur) et le serveur⚓︎
Le Web s'appuie sur un dialogue entre des clients (ex. un téléphone ou un ordinateur doté d'un navigateur) et des serveurs ("gros" ordinateurs hébergeant les ressources). Ainsi, une fois que l'on connaît l'adresse de la ressource que l'on souhaite charger, il nous faut faire une requête (demande) au serveur hébergeant les données du site Web. Pour cela, le client (navigateur) envoient une requête HTTP.

Une fois le requête effectuée, le serveur Web renvoie du code que le navigateur interprète et met en forme pour l'utilisateur. Voici un exemple de code renvoyé :

Répondre aux questions sur la fiche de travail⚓︎
Il est possible de visualiser l'échange entre le navigateur et l'hébergeur du site Web. Pour cela, ouvrir le navigateur Firefox et appuyer sur la touche F12 puis sélectionner l'onglet "Réseau" puis charger la page suivante :
Question 6
Quels les trois types de ressources chargées ?
Question 7
D'après-vous d'où peuvent provenir ces ressources ? Qu'appelle-t-on un serveur ? un client ?
Question 8
Pour quelles ressources le temps de chargement est le plus long ?
Actualiser à présent la page Web en appuyant sur la touche F5.
Question 9
Un code ("État" ou "Statut") est associé à chacune de ces ressources. En vous appuyant sur les ressources présentes sur cette page : https://developer.mozilla.org/fr/docs/Web/HTTP/Status, préciser ce que signifient les codes 200, 304 et 404. Pourquoi sont-ils utiles ?